
大数据时代背景下,数据的价值越来越受到社会各界的重视,各类基于大量数据的信息处理平台不断涌现,而如何实现对信息系统中数据规范化管理及使用,成为摆在众人面前重要的问题。
信息系统,是指由计算机硬件、网络和通讯设备、计算机软件、信息资源、信息用户和规章制度组成的以处理信息流为目的的人机一体化系统。简单地说,信息系统就是输入数据信息,通过加工处理产生信息的系统。
尽管信息系统根据具体搭建目的不同,需要收录、使用的数据也不尽相同,但诸多系统都面临一个共同的问题:平台数据来源多样,格式混乱,阻碍数据进一步使用。
因此,信息治理首先需要解决的就是数据不规范。今日,明朝万达数据专家将以“基于字典树的中文地址信息治理”为例,为您解读数据处理的具体措施。
字典树(单词查找树)应用背景
目前,信息系统中会记录多种地址字段,包括单位地址、收件地址、寄件地址、住所地址等。字段中又包含区域信息(省、市、区/县)和详细信息(街道、街道号/小区名称、楼号、楼层、房间号等)。以上地址信息可用于信息关联、信息统计、信息分类等,具有很大的利用价值。
但是由于地址信息的来源存在多样性、不可控性,导致大量的地址数据不规范,对系统合理充分利用形成了一定的阻碍。因此:
对地址信息进行标准化处理来提高地址信息的利用率,成为信息系统很重要的一项功能。

实现目标
01 区域信息治理
在地址信息中,提取或者还原省、市、区/县信息
在地址信息中,提取区域信息以外的数据,并按照详细规范进行数据格式化输出。
处理过程
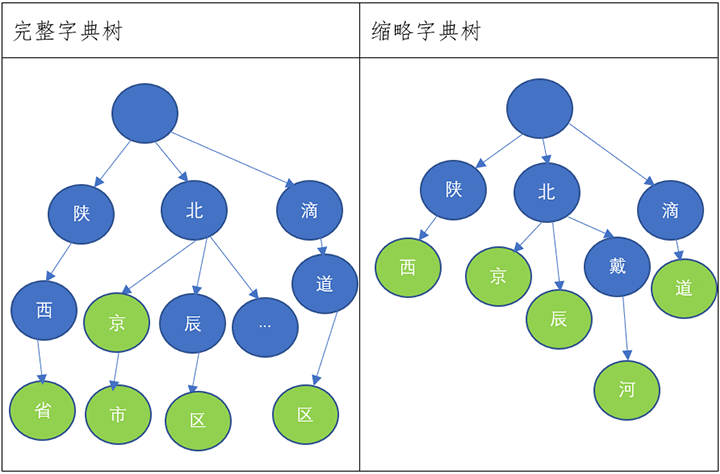
步骤一:使用最新的民政部行政区划代码,构建两棵字典树
※ 绿色代表叶子节点,叶子节点存储完整的区域信息。
举例:在完整字典树中北辰区节点存储:天津,天津市,北辰区;在缩略字典树中西安节点存储:陕西省,西安市&吉林省,辽源市,西安区&黑龙江省,牡丹江市,西安区。
步骤二:区域信息计算
※ 将地址信息在完整字典树中从前向后进行扫描。
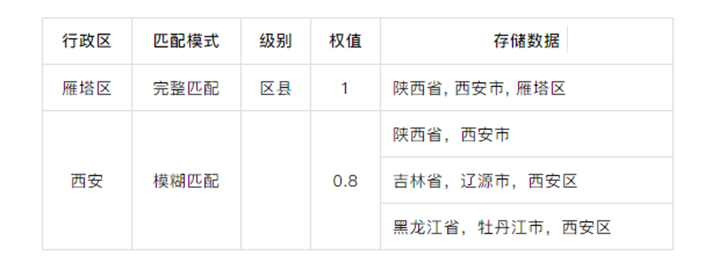
如果命中完整字典树某一个分支,设置阈值1.0, 读取保存的省市区县信息;
※ 接着在缩略字典树中进行扫描。
设置阈值为0.8,由于大部分地区会以某些城市名称作为街道命名,故程序在处理过程中,向后探先探一位,如果包含“街”,“道”,“路”,“乡”,“镇”,“弄”,“坊”等,则将前面命中的一个分支作为详细信息处理。如果包含“东”,“南”,“西”,“北”,“中”,“一”,“二”,“三”,“四”,“五”等,再向后探一位,如果包含“街”,“道”,“路”,“乡”,“镇”,“弄”,“坊”等也作为详细信息处理。
※ 然后对各个省市县信息进行阈值的累加。
※ 最后和完整字典树扫描的结果进行相加,然后就会得出最终的区域信息。
举例:处理地址信息,西安雁塔区科技7路4号
|
|
|

步骤三:详细信息处理
※ 对详细信息进行格式化处理。
使用xx街(路/道/弄等)xx号/小区xx楼xx单元/xx楼xx室,这样的格式对详细信息进行格式化。以上,便是基于字典树的中文地址信息治理方式。
信息系统所收录的地址信息经过字典树处理后,利用程度得到进一步提高,同时提高了系统运作能力,促进集约化管理。
-----

作为中国新一代信息安全技术企业,明朝万达专注数据安全、公共安全、云安全、大数据安全等服务,客户覆盖金融、政府、公安、电信运营商等诸多领域,其中在金融领域数据安全的市场占有率超80%。
明朝万达始终将技术创新作为企业的立足之本,截至2020年6月,公司已申请 300余项发明技术专利,累计授权专利 近100项,多项技术填补了国内空白并达到世界先进水平。


